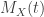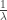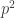An important part of probability theory concerns with the sums of independent random variables. In many situations, the number of terms in the independent sum is itself a random variable.
Introduction
Let ![X_1,X_2,X_3,\cdots]() be a sequence of independent and identically distributed random variables with the common cumulative distribution function (CDF)
be a sequence of independent and identically distributed random variables with the common cumulative distribution function (CDF) ![F_X(x)]() . We consider the sum
. We consider the sum
…(1)…![S=X_1+X_2+\cdots+X_N]()
where the number of terms ![N]() is a random variable independent of the
is a random variable independent of the ![X_j]() . The random variable
. The random variable ![S]() is said to be a compound random variable and its distribution is a compound distribution. To make the compounding more mathematically tractable, we assume the distribution of
is said to be a compound random variable and its distribution is a compound distribution. To make the compounding more mathematically tractable, we assume the distribution of ![N]() does not depend in any way on the values of
does not depend in any way on the values of ![X_1,X_2,X_3,\cdots]() .
.
Here, ![N]() is a count variable counting the occurrence of a certain type of events. When
is a count variable counting the occurrence of a certain type of events. When ![N=n]() , the variable
, the variable ![X_i]() ,
, ![i=1,2,\cdots,n]() , represents some measurement we wish to record for the
, represents some measurement we wish to record for the ![i]() th occurrence of the event. A concrete example is from an insurance perspective. Let
th occurrence of the event. A concrete example is from an insurance perspective. Let ![N]() be the number of insurance claims occurring in a fixed time period (e.g., a year) on a group of insurance contracts or even a single contract. Let
be the number of insurance claims occurring in a fixed time period (e.g., a year) on a group of insurance contracts or even a single contract. Let ![X_i]() be the payment made by the insurer on the
be the payment made by the insurer on the ![i]() th claim. Then compound random variable
th claim. Then compound random variable ![S]() as defined in (1) is a model for the total payments by an insurer. In this insurance application, we assume that the claim size variables
as defined in (1) is a model for the total payments by an insurer. In this insurance application, we assume that the claim size variables ![X_1,X_2,\cdots]() are independent and identically distributed and that the claim count
are independent and identically distributed and that the claim count ![N]() and the claim sizes
and the claim sizes ![X_1,X_2,\cdots]() are independent. The random variable
are independent. The random variable ![S]() in the context of total insurance payments is often referred to as the aggregate claim random variable or aggregate loss random variable. See here for a more concise introduction of the notion of compound distributions.
in the context of total insurance payments is often referred to as the aggregate claim random variable or aggregate loss random variable. See here for a more concise introduction of the notion of compound distributions.
We focus on some of the mathematical properties of the compound random variables ![S]() . We first examine an example before proceeding further.
. We first examine an example before proceeding further.
Example 1
Consider the random variable ![N]() with probabilities
with probabilities ![P(N=0)=\frac{1}{4}]() ,
, ![P(N=1)=\frac{1}{2}]() and
and ![P(N=2)=\frac{1}{4}]() . Note that
. Note that ![N]() has a binomial distribution with 2 trials and probability of success
has a binomial distribution with 2 trials and probability of success ![\frac{1}{2}]() . The independent random variables
. The independent random variables ![X_1,X_2,\cdots]() are uniformly distributed on the interval
are uniformly distributed on the interval ![(0,1)]() . When we define
. When we define ![S]() according to (1),
according to (1), ![S]() would be an insurance payment model with the claim count modeled by a binomial distribution and the claim size modeled by the uniform distribution on the unit interval
would be an insurance payment model with the claim count modeled by a binomial distribution and the claim size modeled by the uniform distribution on the unit interval ![(0,1)]() .
.
Because there can be only 0, 1 or 2 terms, it is quite easy to visualize the compound variable ![S=X_1+\cdots+X_N]() . When
. When ![N=0]() ,
, ![S=0]() (a single point mass). When
(a single point mass). When ![N=1]() ,
, ![S]() has a uniform distribution. When
has a uniform distribution. When ![N=2]() ,
, ![S]() is simply an independent sum of two unform random variables. The CDF of
is simply an independent sum of two unform random variables. The CDF of ![S]() in this case is the weighted average of the following three CDFs.
in this case is the weighted average of the following three CDFs.
….![\displaystyle F_0^*(x) = \left\{ \begin{array}{ll} 0&\ \ \ \ \ \ x < 0 \\ \text{ } & \text{ } \\ 1&\ \ \ \ \ \ 0 \le x < \infty \end{array} \right.]()
….![\displaystyle F_1^*(x) = \left\{ \begin{array}{ll} 0&\ \ \ \ \ \ x < 0 \\ \text{ } & \text{ } \\ x&\ \ \ \ \ \ 0 \le x < 1 \\ \text{ } & \text{ } \\ 1&\ \ \ \ \ \ 1 \le x < \infty \end{array} \right.]()
….![\displaystyle F_2^*(x) = \left\{ \begin{array}{ll} 0&\ \ \ \ \ \ x < 0 \\ \text{ } & \text{ } \\ \displaystyle \frac{x^2}{2}&\ \ \ \ \ \ 0 \le x < 1 \\ \text{ } & \text{ } \\ \displaystyle 1-\frac{(2-x)^2}{2}&\ \ \ \ \ \ 1 \le x < 2 \\ \text{ } & \text{ } \\ 1&\ \ \ \ \ \ 2 \le x < \infty \end{array} \right.]()
The CDF ![F_0^*(x)]() is for the point mass at 0, the case of probability 1 being assigned to
is for the point mass at 0, the case of probability 1 being assigned to ![S=0]() conditioning that
conditioning that ![N=0]() . The CDF
. The CDF ![F_1^*(x)]() is simply the CDF of the uniform distribution reflecting the case of
is simply the CDF of the uniform distribution reflecting the case of ![N=1]() , in which case
, in which case ![S]() has the uniform distribution. The CDF
has the uniform distribution. The CDF ![F_2^*(x)]() is that of the independent sum of two uniform distributions on the interval
is that of the independent sum of two uniform distributions on the interval ![(0,1)]() . The CDF of the compound
. The CDF of the compound ![S]() is the weighted average of these CDFs.
is the weighted average of these CDFs.
….(*)….![F_S(s)=F_0(s) \cdot P(N=0)+F_1(s) \cdot P(N=1)+F_2(s) \cdot P(N=2)]()
The explicit description of the CDF is
….![\displaystyle F_S(s) = \left\{ \begin{array}{ll} 0&\ \ \ \ \ \ s < 0 \\ \text{ } & \text{ } \\ \displaystyle \frac{1}{4}+\frac{1}{2} s+\frac{1}{8} s^2&\ \ \ \ \ \ 0 \le s < 1 \\ \text{ } & \text{ } \\ \displaystyle 1-\frac{1}{8} (2-s)^2&\ \ \ \ \ \ 1 \le s < 2 \\ \text{ } & \text{ } \\ 1&\ \ \ \ \ \ 2 \le s < \infty \end{array} \right.]()
Note that the support of ![S]() is the interval
is the interval ![(0,2)]() . In the interval
. In the interval ![[0,1)]() , we take the weighted average of 1 (with probability
, we take the weighted average of 1 (with probability ![\frac{1}{4}]() ),
), ![F_1^*]() (with probability
(with probability ![\frac{1}{2}]() ) and
) and ![F_2^*]() (with probability
(with probability ![\frac{1}{4}]() ). In the interval
). In the interval ![[1,2)]() , we take the weighted average of 1 (with probability
, we take the weighted average of 1 (with probability ![\frac{1}{4}]() ), 1 (with probability
), 1 (with probability ![\frac{1}{2}]() ) and
) and ![F_2^*]() (with probability
(with probability ![\frac{1}{4}]() ). Also note that the distribution of
). Also note that the distribution of ![S]() is neither a continuous nor a discrete distribution. It is a mixed distribution. It has a point mass at
is neither a continuous nor a discrete distribution. It is a mixed distribution. It has a point mass at ![s=0]() with probability
with probability ![\frac{1}{4}]() (note the jump of size
(note the jump of size ![\frac{1}{4}]() in the CDF). This point mass corresponds with the case of
in the CDF). This point mass corresponds with the case of ![S=0]() . It also has a positive density curve in the interval
. It also has a positive density curve in the interval ![(0,2)]() with no points in this interval having positive probability. The probability density function of
with no points in this interval having positive probability. The probability density function of ![S]() is
is
….![\displaystyle f_S(s) = \left\{ \begin{array}{ll} \displaystyle \frac{1}{4}&\ \ \ \ \ \ s = 0 \\ \text{ } & \text{ } \\ \displaystyle \frac{1}{4} \ (2+s)&\ \ \ \ \ \ 0 < s < 1 \\ \text{ } & \text{ } \\ \displaystyle \frac{1}{4} \ (2-s)&\ \ \ \ \ \ 1 \le s < 2 \\ \end{array} \right.]()
Once the CDF and the density function are known, many distributional quantities of ![S]() can be obtained. For example, the mean and variance of
can be obtained. For example, the mean and variance of ![S]() are
are ![E(S)=\frac{1}{2}]() and
and ![Var(S)=\frac{5}{24}]() .
.
CDF of the Compound Random Variable
According to the idea outlined in (*) in Example 1, the CDF of a compound random variable is the weighted average of the CDFs of the independent sums of the ![X]() variables. The CDF of the compound random variable as defined in (1) is
variables. The CDF of the compound random variable as defined in (1) is
….(2)….![\displaystyle \begin{aligned}F_S(s)&=P(S \le s) \\&=\sum_{n=0}^\infty \biggl[ P(S \le s \lvert N=n) \times P(N=n) \biggr]\\&=\sum_{n=0}^\infty \biggl[ F_n^*(s) \times P(N=n) \biggr] \end{aligned}]()
where ![F_n^*(s)]() is the CDF of the independent sum
is the CDF of the independent sum ![X_1+\cdots+X_n]() for all
for all ![n \ge 1]() and
and ![F_0^*(s)]() is the CDF of a single point mass at
is the CDF of a single point mass at ![s=0]() defined below.
defined below.
….![\displaystyle F_0^*(s) = \left\{ \begin{array}{ll} 0&\ \ \ \ \ \ s < 0 \\ \text{ } & \text{ } \\ 1&\ \ \ \ \ \ 0 \le s < \infty \end{array} \right.]()
The CDF ![F_n^*(s)]() is called the
is called the ![n]() -fold convolution and defined recursively. In the next section, we discuss briefly the notion of convolution.
-fold convolution and defined recursively. In the next section, we discuss briefly the notion of convolution.
Convolution – Continuous Case
In probability theory, convolution is a mathematical operation that allows us to derive the distribution of a sum of two independent random variables from the two individual distributions. We consider the continuous case in this section and the discrete case in the next section.
Suppose ![T_1]() and
and ![T_2]() are independent continuous random variables probability density functions (PDF)
are independent continuous random variables probability density functions (PDF) ![f(t)]() and
and ![g(t)]() and cumulative distribution function (CDF)
and cumulative distribution function (CDF) ![F(t)]() and
and ![G(t)]() , respectively. The PDF and the CDF of the independent sum
, respectively. The PDF and the CDF of the independent sum ![T=T_1+T_2]() are
are
….(3)….![\displaystyle f_T(t)=\int_{-\infty}^\infty f(x) g(t-x) \ dx=\int_{-\infty}^\infty g(x) f(t-x) \ dx]()
….(4)….![\displaystyle F_T(t)=\int_{-\infty}^\infty f(x) G(t-x) \ dx=\int_{-\infty}^\infty g(x) F(t-x) \ dx]()
The following gives the derivation of the first form of the CDF in (4). The second form is derived analogously.
….![\displaystyle \begin{aligned}F_T(t)&=P(T \le t)=P(T_1+T_2 \le t) \\&=\int_{-\infty}^\infty P(T_1+T_2 \le t \ \lvert \ T_1=x) \times f(x) \ dx\\&=\int_{-\infty}^\infty P(x+T_2 \le t \ \lvert \ T_1=x) \times f(x) \ dx \\&=\int_{-\infty}^\infty P(T_2 \le t-x \ \lvert \ T_1=x) \times f(x) \ dx \\&=\int_{-\infty}^\infty P(T_2 \le t-x) \times f(x) \ dx \\&=\int_{-\infty}^\infty G(t-x) \times f(x) \ dx \end{aligned}]()
Even though the integral in (4) is stated to be from ![-\infty]() to
to ![\infty]() , in practice it only needs to be over the support of
, in practice it only needs to be over the support of ![T_1]() , which could be some subinterval of
, which could be some subinterval of ![(-\infty,\infty)]() . The PDF in (3) is obtained by differentiating the CDF in (4).
. The PDF in (3) is obtained by differentiating the CDF in (4).
….![\displaystyle f_T(t)=\frac{d}{dt} F_T(t)=\int_{-\infty}^\infty f(x) g(t-x) \ dx]()
The convolution of more than two independent random variables is derived recursively. For example, the distribution of the sum of three independent random variables is the convolution of the distribution of the first random variable and the distribution of the sum of the second and third variables. Analogously, the distribution of the sum of ![n]() independent random variables is the convolution of the first random variable and the distribution of the independent sum of the
independent random variables is the convolution of the first random variable and the distribution of the independent sum of the ![n-1]() random variables from the second to the
random variables from the second to the ![n]() th one. Suppose
th one. Suppose ![X_1,X_2,\cdots,X_n]() are independent and identically distributed with common CDF
are independent and identically distributed with common CDF ![F_X(x)]() and PDF
and PDF ![f_X(x)]() . We denote the CDF and PDF of the independent sum
. We denote the CDF and PDF of the independent sum ![X_1+\cdots+X_n]() by
by ![F_n^*(s)]() and
and ![f_n^*(s)]() , respectively. For
, respectively. For ![n > 1]() , they are
, they are
….(5)….![\displaystyle f_n^*(s)=\int_{-\infty}^\infty f_{n-1}^*(s-x) \ f_X(x) \ dx]()
….(6)….![\displaystyle F_n^*(s)=\int_{-\infty}^\infty F_{n-1}^*(s-x) f_X(x) \ dx]()
The results in (5) and (6) follow from (3) and (4). If the random variables ![X_1,X_2,\cdots]() only take on positive values, then the convolution results in (5) and (6) can be simplified as the following.
only take on positive values, then the convolution results in (5) and (6) can be simplified as the following.
….(7)….![\displaystyle f_n^*(s)=\int_{0}^s f_{n-1}^*(s-x) \ f_X(x) \ dx]()
….(8)….![\displaystyle F_n^*(s)=\int_{0}^s F_{n-1}^*(s-x) f_X(x) \ dx]()
The convolution results in (7) and (8) would be appropriate for the insurance context of total payments since the claim size would only take on positive values.
Convolution – Discrete Case
In the discrete case, we derive the convolution of two probability functions. Suppose that ![Y]() and
and ![Z]() are two independent random variables taking on the integers (or some appropriate subset) with probability functions
are two independent random variables taking on the integers (or some appropriate subset) with probability functions ![P_Y(y)=P(Y=y)]() and
and ![P_Z(z)=P(Z=z)]() , respectively. The probability function of the independent sum
, respectively. The probability function of the independent sum ![W=Y+Z]() is
is
….(9)….![\displaystyle P_W(w)=\sum_{y}^{\text{ }} P_Y(y) P_Z(w-y)=\sum_{z}^{\text{ }} P_Y(w-y) P_Z(z)]()
The following gives the derivation of the first form of (9). the second form is derived analogously.
….![\displaystyle \begin{aligned}P_W(w)&=P(W=w)=P(Y+Z=w) \\&=\sum_{y} P(Y=y,W=w)\\&=\sum_{y} P(Y=y,Z=w-y) \\&=\sum_{y} P(Y=y) P(Z=w-y) \\&=\sum_{y} P_Y(y) P_Z(w-y) \end{aligned}]()
Once the probability function ![P_W(w)]() is obtained, the CDF of
is obtained, the CDF of ![W]() is obtained by definition, i.e.,
is obtained by definition, i.e., ![F_W(w)=P(W \le w)]() . In the discrete case (as in the continuous case), the convolution of more than two random variables is also derived recursively. Suppose
. In the discrete case (as in the continuous case), the convolution of more than two random variables is also derived recursively. Suppose ![X_1,X_2,\cdots,X_n]() are independent and identically distributed random variables with common probability function
are independent and identically distributed random variables with common probability function ![P_X(x)=P(X=x)]() . We denote the probability function of the independent sum
. We denote the probability function of the independent sum ![X_1+\cdots+X_n]() be
be ![P_n^*(s)]() . For
. For ![n > 1]() , it is
, it is
….(10)….![\displaystyle P_n^*(s)=P(X_1+\cdots+X_n=s)=\sum_{x} P_{n-1}^* (s-x) P_X(s)]()
Note that in (10) the summation ranges over the integer values. If the random variables ![X_1,X_2,\cdots]() only take on positive integers, then (10) can be simplified as
only take on positive integers, then (10) can be simplified as
….(11)….![\displaystyle P_n^*(s)=P(X_1+\cdots+X_n=s)=\sum_{x=1}^\infty P_{n-1}^* (s-x) P_X(s)]()
The convolution result in (11) would be appropriate in the insurance context of total claim payments. If the variables ![X_1,X_2,\cdots]() only take on non-negative integers, then the summation in (11) starts at
only take on non-negative integers, then the summation in (11) starts at ![x=0]() . Once the convolution result of the probability function
. Once the convolution result of the probability function ![P_n^*(s)]() is derived, the CDF is defined accordingly,
is derived, the CDF is defined accordingly,
….(12)….![\displaystyle F_n^*(s)=P(X_1+\cdots+X_n \le s)=\sum_{x \le s} P_n^*(x)]()
Back to Distribution of the Compound Random Variable
The result (2) above shows that the CDF of the compound random variable ![S]() is the weighted average of the convolution CDFs of independent sums of the
is the weighted average of the convolution CDFs of independent sums of the ![X]() variables. The weighting is the probability function of the count random variable
variables. The weighting is the probability function of the count random variable ![N]() . The CDF in (2) is applicable when the
. The CDF in (2) is applicable when the ![X]() random variable is discrete and when
random variable is discrete and when ![X]() is continuous. In the remainder of this discussion, we assume that
is continuous. In the remainder of this discussion, we assume that ![X]() only takes on positive values if it is continuous and only takes on positive integers (when
only takes on positive values if it is continuous and only takes on positive integers (when ![X]() is continuous). To repeat, the CDF of
is continuous). To repeat, the CDF of ![S]() is
is
….(13)….![\displaystyle \begin{aligned}F_S(s)&=P(S \le s) \\&=\sum_{n=0}^\infty \biggl[ P(S \le s \lvert N=n) \times P(N=n) \biggr]\\&=\sum_{n=0}^\infty \biggl[ F_n^*(s) \times P(N=n) \biggr] \end{aligned}]()
Now that ![X]() only takes on positive values or positive integers, note that when
only takes on positive values or positive integers, note that when ![X]() is continuous, the convolution CDF
is continuous, the convolution CDF ![F_n^*(s)]() is based on (8). When
is based on (8). When ![X]() is discrete,
is discrete, ![F_n^*(s)]() is based on (12). The PDF of
is based on (12). The PDF of ![S]() (when
(when ![X]() is continuous) and the probability function of
is continuous) and the probability function of ![S]() (when
(when ![X]() is discrete) are
is discrete) are
….(14)….![\displaystyle f_S(s) = \left\{ \begin{array}{ll} P(N=0)&\ \ \ \ \ \ s= 0 \\ \text{ } & \text{ } \\ \displaystyle \sum_{n=1}^\infty f_n^*(s) \times P(N=n)&\ \ \ \ \ \ s > 0 \end{array} \right.]()
….(15)….![\displaystyle P_S(s)=P(S=s) = \left\{ \begin{array}{ll} P(N=0)&\ \ \ \ \ \ s= 0 \\ \text{ } & \text{ } \\ \displaystyle \sum_{n=1}^\infty P_n^*(s) \times P(N=n)&\ \ \ \ \ \ s=1,2,3,\cdots \end{array} \right.]()
Note that in both (13) and (14), there is a point mass at ![s=0]() , modeling the case where there is no occurrence of the event of interest (
, modeling the case where there is no occurrence of the event of interest (![N=0)]() . Thus the size of the jump at the point mass in the CDF is
. Thus the size of the jump at the point mass in the CDF is ![P(N=0)]() .
.
The mean and variance of the compound random variable ![S]() are
are
….(16)….![\displaystyle E(S)=E(N) \cdot E(X)]()
….(17)….![\displaystyle Var(S)=E(N) \cdot Var(X)+Var(N) \cdot E(X)^2]()
Because CDF of ![S]() is a weighted average of the CDFs of distributions, many distributional quantities such as mean and higher moments can be obtained by performing weighted averaging. Here’s the derivation of
is a weighted average of the CDFs of distributions, many distributional quantities such as mean and higher moments can be obtained by performing weighted averaging. Here’s the derivation of ![E(S)]() .
.
….![\displaystyle \begin{aligned}E(S)&=E_N[E(S \lvert N)] \\&=E_N[E(X_1+\cdots+X_N \lvert N)]\\&=E_N[ N \cdot E(X)] \\&=E(N) E(X) \end{aligned}]()
The above derivation makes use of two levels of expectation, one for the random variable ![N]() and one for the random variable
and one for the random variable ![X]() . It also makes use of the assumption that
. It also makes use of the assumption that ![N]() and
and ![X]() are independent. The expected value of
are independent. The expected value of ![S]() has a natural interpretation. It is the product of the expected number of events (e.g., occurrences of claims) and the expected individual measurements (e.g., claim sizes).
has a natural interpretation. It is the product of the expected number of events (e.g., occurrences of claims) and the expected individual measurements (e.g., claim sizes).
The variance of ![S]() also has a natural interpretation. It is the sum of two components such that the first component stems from the variability of
also has a natural interpretation. It is the sum of two components such that the first component stems from the variability of ![X]() and the second component stems from the variability of
and the second component stems from the variability of ![N]() . See here for the derivation of (17). The moment generating function of
. See here for the derivation of (17). The moment generating function of ![S]() is
is
….(18)….![\displaystyle M_S(t)=M_N[ \log M_X(t)]]()
where ![M_N(t)]() is the moment generating function of
is the moment generating function of ![N]() and
and ![M_X(t)]() is the moment generating function of
is the moment generating function of ![X]() . See here for a derivation.
. See here for a derivation.
More Examples
Example 2
We use the insurance context discussed above. The number of claims ![N]() in a policy period for an insurance policy is modeled by the binomial distribution with
in a policy period for an insurance policy is modeled by the binomial distribution with ![n=2]() trials and probability of success
trials and probability of success ![p]() . The individual claim size
. The individual claim size ![X]() is modeled by the exponential distribution with mean
is modeled by the exponential distribution with mean ![\frac{1}{\lambda}]() . Derive the CDF and the PDF of the aggregate payment
. Derive the CDF and the PDF of the aggregate payment ![S=X_1+\cdots+X_n]() as well as the mean and variance and the moment generating function.
as well as the mean and variance and the moment generating function.
Since ![N]() can only be 0, 1 or 2, the CDF of
can only be 0, 1 or 2, the CDF of ![S]() is
is
….![\displaystyle F_S(s)=(1-p)^2+2p (1-p) (1-e^{-\lambda s})+p^2 (1-\lambda x e^{-\lambda x}-e^{-\lambda x}]() ;….
;….![s \ge 0]()
The CDF is the weighted average of three quantities, 1 (with probability ![p^2]() ), the CDF of the exponential distribution (with probability
), the CDF of the exponential distribution (with probability ![2 p (1-p)]() ), and the CDF of a gamma distribution that is the independent sum of two exponential distributions (with probability
), and the CDF of a gamma distribution that is the independent sum of two exponential distributions (with probability ![p^2]() ). The PDF of
). The PDF of ![S]() is
is
….![\displaystyle f_S(s) = \left\{ \begin{array}{ll} \displaystyle (1-p)^2&\ \ \ \ \ \ s = 0 \\ \text{ } & \text{ } \\ \displaystyle 2p(1-p) \lambda e^{-\lambda s}+p^2 (\lambda^2 s e^{-\lambda s})&\ \ \ \ \ \ s > 0 \\ \end{array} \right.]()
Note that there is a point mass at ![s=0]() with probability
with probability ![(1-p)^2]() . In the continuous part, the density function is a weighted average of the exponential and gamma density functions. The mean and variance are calculated according to (16) and (17).
. In the continuous part, the density function is a weighted average of the exponential and gamma density functions. The mean and variance are calculated according to (16) and (17).
….![\displaystyle E(S)=\frac{2p}{\lambda}]()
….![\displaystyle Var(S)=\frac{4p-2p^2}{\lambda^2}]()
The moment generating functions of ![N]() ,
, ![X]() and
and ![S]() are
are
….![\displaystyle M_N(t)=(1-p+p e^t)^2]()
….![\displaystyle M_X(t)=\frac{\lambda}{\lambda-t}]() ;….
;….![t < \lambda]()
….![\displaystyle \begin{aligned}M_S(t)&=M_N(\log M_X(t)) \\&=(1-p+p \frac{\lambda}{\lambda-t})^2\\&=(1-p)^2+2 p (1-p) \ \frac{\lambda}{\lambda-t}+p^2 \biggl(\frac{\lambda}{\lambda-t} \biggr)^2 \end{aligned}]()
As expected, the moment generating of the compound random variable ![S]() is the weighted average of three appropriate moment generating functions. For a more detailed discussed of this example, see here.
is the weighted average of three appropriate moment generating functions. For a more detailed discussed of this example, see here.
Example 3
The compound random variable ![S]() in both Example 1 and Example 2 can be completely described since the count variable can only take on 0, 1 or 2 and since the
in both Example 1 and Example 2 can be completely described since the count variable can only take on 0, 1 or 2 and since the ![X]() variable is a familiar distribution that is mathematically tractable. We now present a compound distribution that cannot be completely described analytically. Let
variable is a familiar distribution that is mathematically tractable. We now present a compound distribution that cannot be completely described analytically. Let ![N]() be a Poisson random variable with mean
be a Poisson random variable with mean ![\lambda]() . Suppose that
. Suppose that ![X]() is the random variable such that
is the random variable such that ![P(X=1)=0.6]() and
and ![P(X=2)=0.4]() . Let
. Let ![S]() be the total insurance payment variable
be the total insurance payment variable ![S=X_1+\cdots+X_N]() . The distribution of
. The distribution of ![S]() would be a discrete distribution taking on the non-negative integers. Determine
would be a discrete distribution taking on the non-negative integers. Determine ![P(S=s)]() for
for ![s=0,1,2,3,4]() .
.
Since ![N]() has a Poisson distribution, the random variable
has a Poisson distribution, the random variable ![S]() is said to have a compound Poisson distribution. See here for a discussion of this example.
is said to have a compound Poisson distribution. See here for a discussion of this example.
Remarks
Compound distributions have many natural applications. Compound distributions also represent a versatile modeling tool. For further information on the topic of compound distributions, see these articles in a companion site: here (a more concise introduction), here (examples), here (compound Poisson distribution), here (example of compound Poisson), here (compound negative binomial distribution), here (examples of mixed distributions), here (compound Poisson mixed distribution), and here (Bayesian prediction).
Dan Ma Compound Distribution
Daniel Ma Compound Distribution
Dan Ma Compound Random Variable
Daniel Ma Compound Random Variable
Dan Ma Aggregate Loss Random Variable
Daniel Ma Aggregate Loss Random Variable
Dan Ma Convolution
Daniel Ma Convolution
Dan Ma Convolution of Probability Distributions
Daniel Ma Convolution of Probability Distributions
![\copyright]() 2025 – Dan Ma
2025 – Dan Ma
Posted: March 21, 2025

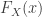


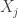

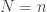

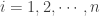










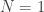










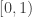




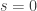




![\displaystyle \begin{aligned}F_S(s)&=P(S \le s) \\&=\sum_{n=0}^\infty \biggl[ P(S \le s \lvert N=n) \times P(N=n) \biggr]\\&=\sum_{n=0}^\infty \biggl[ F_n^*(s) \times P(N=n) \biggr] \end{aligned}](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7DF_S%28s%29%26%3DP%28S+%5Cle+s%29+%5C%5C%26%3D%5Csum_%7Bn%3D0%7D%5E%5Cinfty+%5Cbiggl%5B+P%28S+%5Cle+s+%5Clvert+N%3Dn%29+%5Ctimes+P%28N%3Dn%29+%5Cbiggr%5D%5C%5C%26%3D%5Csum_%7Bn%3D0%7D%5E%5Cinfty+%5Cbiggl%5B+F_n%5E%2A%28s%29+%5Ctimes+P%28N%3Dn%29+%5Cbiggr%5D++%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)


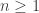





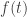

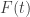







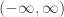





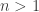


















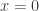








![\displaystyle \begin{aligned}E(S)&=E_N[E(S \lvert N)] \\&=E_N[E(X_1+\cdots+X_N \lvert N)]\\&=E_N[ N \cdot E(X)] \\&=E(N) E(X) \end{aligned}](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7DE%28S%29%26%3DE_N%5BE%28S+%5Clvert+N%29%5D+%5C%5C%26%3DE_N%5BE%28X_1%2B%5Ccdots%2BX_N+%5Clvert+N%29%5D%5C%5C%26%3DE_N%5B+N+%5Ccdot+E%28X%29%5D+%5C%5C%26%3DE%28N%29+E%28X%29++%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle M_S(t)=M_N[ \log M_X(t)]](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+M_S%28t%29%3DM_N%5B+%5Clog+M_X%28t%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)